

Deep Learning on Embedded Systems
As Artificial Intelligence (AI) expands into almost every aspect of our life, one of the major challenges is to bring this intelligence into small, low-power devices. This requires embedded platforms that can process extremely deep Neural Networks (NN) with high performance and very low power consumption. However, this is still not enough. Machine Learning developers need a quick and automated way to convert, optimize and execute their pre-trained networks on such embedded platforms. In this series of posts, we will review the current frameworks and the challenges they pose for embedded systems, and demonstrate our solution to tackling these challenges. These posts are your guide to accomplishing this task within minutes, rather than spending months on manual porting and optimizations.
The links to the different parts will be updated, as they are posted.
Part 1: Deep Learning Frameworks, Features, and Challenges
Part 2: How to Overcome the Deep Learning Challenges in Embedded Platforms
Part 3: CDNN – Generating a Network at the Push of a Button
Part 1: Deep Learning Frameworks, Features, and Challenges
Until recently, the main limitations on deep learning and its applications in real life have been computing horsepower, power constraints, and algorithmic quality. Enormous progress on each of these fronts has led to outstanding achievements in many different fields, like image classification, speech, and natural language processing to name a few. For a concrete example in image classification, we can look at the dramatic improvement by a factor of four on the ImageNet database, in the last five years. Deep learning techniques had reached a 16% top-5 error rate in 2012, and are now below 5%, exceeding human performance! For a little more introductory information about neural networks and deep learning frameworks, you can read this recent post on the subject.
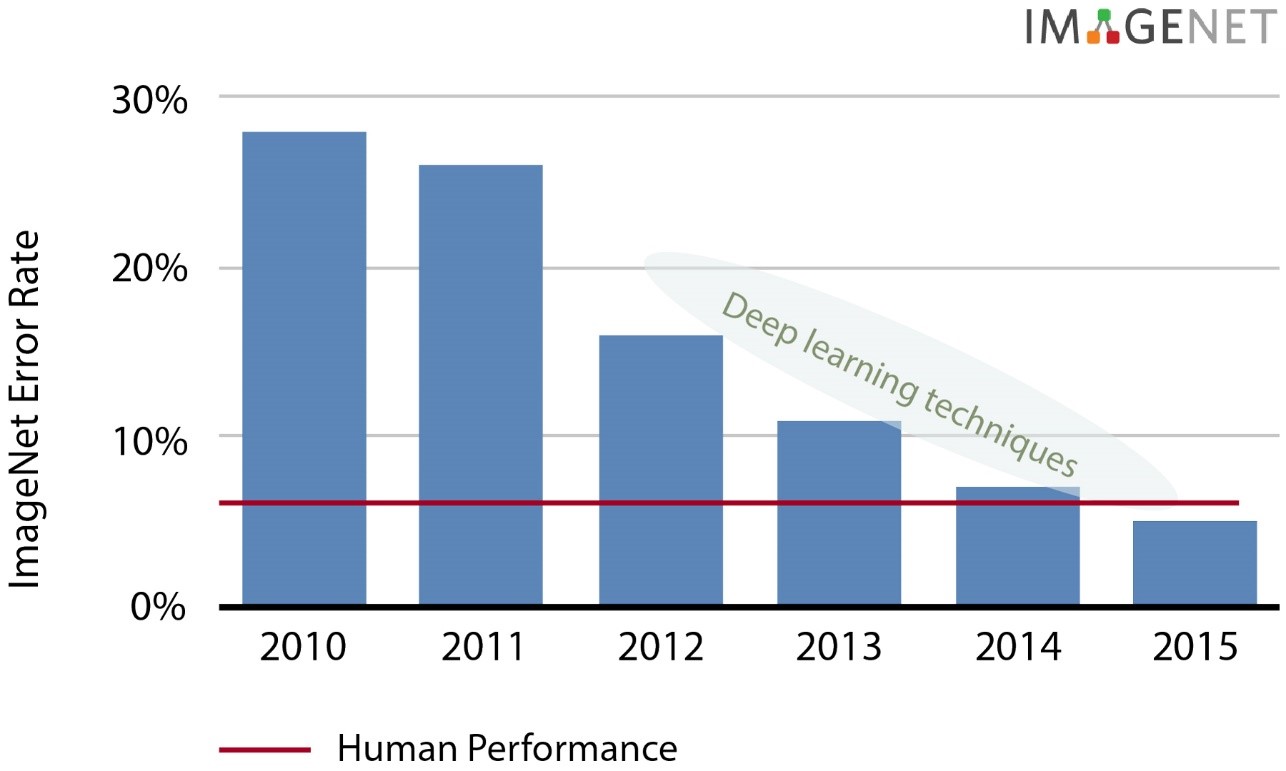
Deep Learning techniques have led to significant performance improvements in recent years (Source: Nervana)
The challenges of neural networks
Transferring these accomplishments into mobile, handheld devices is clearly the next evolutionary step for this technology. However, doing so poses quite a few challenges. First, there are numerous competing frameworks. Two of the leading and most well-known ones are Caffe, developed at UC Berkeley, and TensorFlow, recently released by Google. In addition to these, many other frameworks are available such as the Computational Network Toolkit (CNTK) by Microsoft, Torch, Chainer, and more.
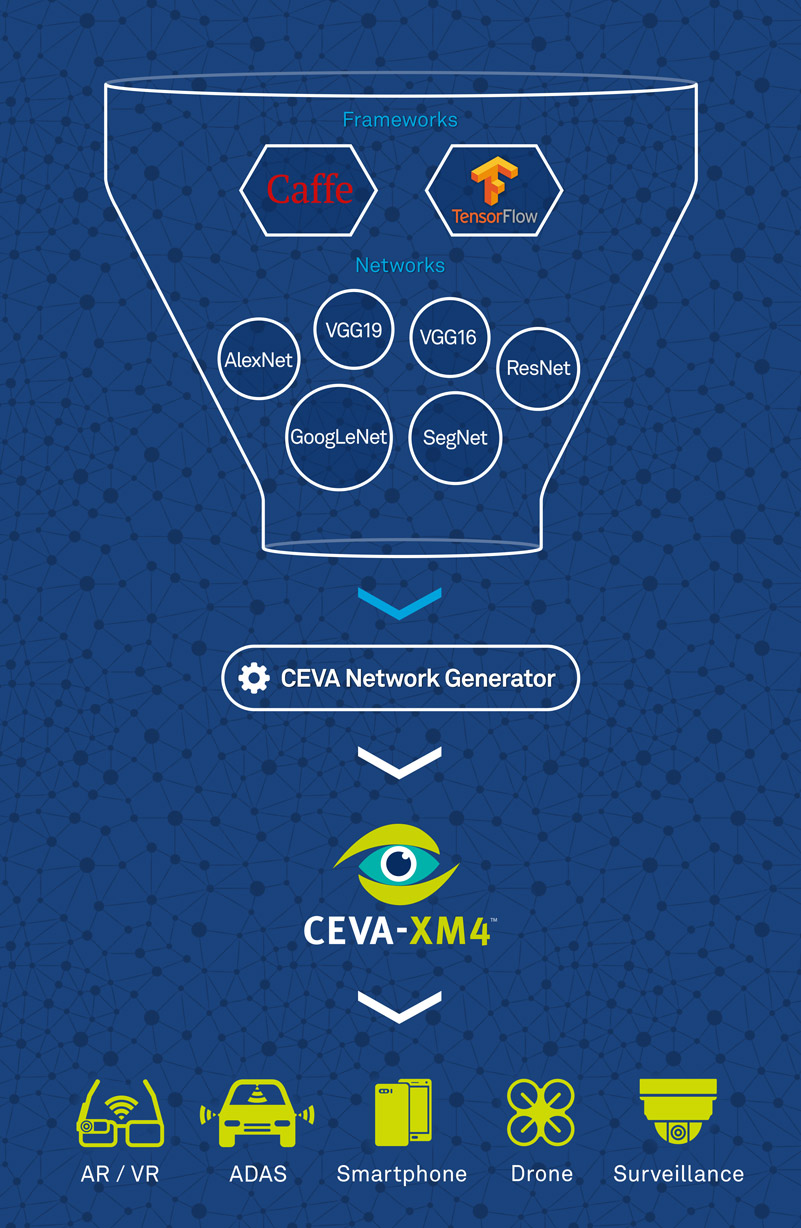
In addition to the numerous frameworks, neural networks include various types of layers, such as Convolutional, Normalization, Pooling and others. A further hindrance is the multitude of network topologies. Until recently, neural networks all followed one simple topology. Today, the situation is much more complex, with network-inside-a-network topologies. For example, GoogLeNet, includes nine inceptions, creating a very rich and complex topology.
Additional complications include supporting a variable size region of interest (ROI). While research-oriented networks, such as AlexNet, work on a fixed size ROI, commercial networks will have to be more flexible for optimized, suitable solutions.
Leading deep learning frameworks
Let’s take a little closer look at two of the leading frameworks, Caffe and TensorFlow. Comparing these two frameworks will shed some light on the advantages and disadvantages of each.
Maturity
Caffe has been around a little longer. Introduced back in summer 2014, it benefits from a large repository of pre-trained neural network models supporting a variety of image classification tasks, named the Model Zoo. TensorFlow, in contrast, was first introduced more recently, in November 2015.
Applicability
Caffe is used for image classification, while not targeted for other deep-learning applications such as text or sound. Adversely, TensorFlow is capable of addressing general applications, in addition to image classification.
Modeling Capabilities
Recurrent neural networks (RNNs) are networks that retain previous states to achieve persistence, similar to the human thought process.. Caffe is not very flexible in this sense, as its legacy architecture requires defining the full forward, backward, and gradient update for each new layer type. Since TensorFlow uses a symbolic graph of vector operations approach, specifying a new network is fairly easy.
Architecture
TensorFlow has a cleaner, modular architecture with multiple front-ends and execution platforms.
Layers of the leading neural networks
A convolutional neural network (CNN) is a special case of a neural network. A CNN consists of one or more convolutional layers, often with a subsampling layer, which are followed by one or more fully connected layers as in a standard neural network. In CNNs, the weights of the convolutional layer used for feature extraction as well as the fully connected layer used for classification are determined during the training process. The total number of layers in a CNN may vary from a few layers to approximately 24 in the case of AlexNet, and up to even 90 layers in the case of SegNet.
Based on the multiple networks that we encountered during our work with our customers and partners, we have compiled a list of some the leading layers.
- Convolutional
- Normalization
- Pooling (Average and Max)
- Fully Connected
- Activation (ReLU, Parametric ReLU, TanH, Sigmoid)
- Deconvolution
- Concatenation
- Upsample
- Argmax
- Softmax
As NNs continue to evolve, this list is likely to change and shift, as well. A viable embedded solution can’t afford to become defunct each time deep learning algorithms advance. The key to avoiding this is having the flexibility to evolve with it, and cope with the new layers. This type of flexibility is exhibited by the CEVA-XM4 vision DSP processor that was presented by CEVA during the last CES running real-time Alexnet with all its 24 layers.
Deep Learning Topologies
If we take a look at networks such as AlexNet or on the different VGG networks, they all have the same simple topology named linear network. In this topology, each neuron point has a single input and a single output.
A more complex topology includes multiple layers per level. In this case, the work is divided between several neurons that are at the same level, and then combined to another neuron. An example of such network for is GoogLeNet. Additional complexity is introduced by networks that have Multiple-Input-Multiple-Output topology.
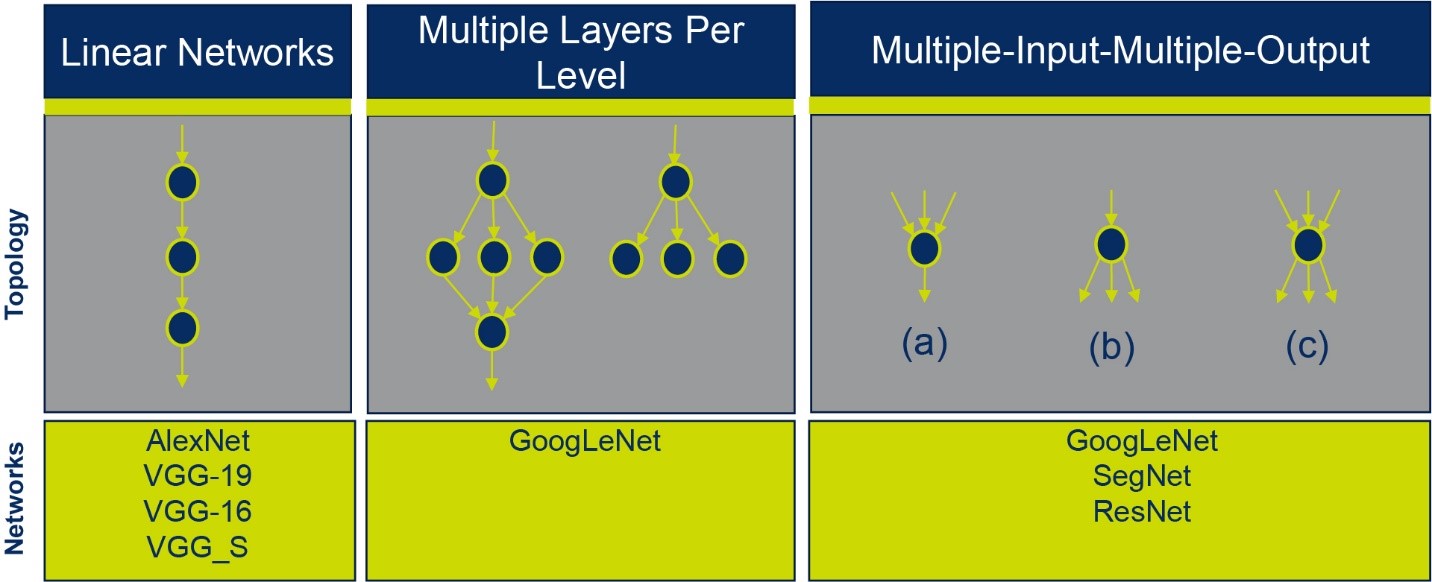
Deep learning typologies (Source: CEVA)
As we can see in this case (c) in the above figure, the same neuron can receive and send multiple inputs and outputs at the same time. These types of networks are exemplified by GoogLeNet, SegNet and ResNet.
On top of these topologies, there are fully convolutional networks, which are fast, end to-end models for pixel-wise problems. Fully convolutional networks can receive an input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. This is more suitable for commercial applications where the ROI dynamically changes depending on the object size.
Challenges of embedded neural networks
Following the pre-trained network, the next big challenge is implementing it in embedded systems, which could be a challenging task! The obstacles can be divided into two parts:
- Limits on the bandwidth and computing capacity of embedded systems.
NNs require a lot of data to be transferred between layers using DDR. In the case of convolution and fully connected data weights from DDR, the data transfer can be very large. In these cases, floating point precision is used, as well. In many cases, the same network is used to process multiple ROIs. While large, power-hungry machines can perform these tasks, embedded platforms have strict limitations. To achieve cost-effectiveness, low power, and minimal size, embedded solutions use less data, have limited memory size, and typically work in integer precision, as opposed to floating point. - The effort of porting and optimizing NNs for embedded platforms.
The task of porting a pre-trained NN to an embedded platform is time consuming, and requires programming knowledge and experience in the target platform. After the preliminary porting is completed, it must also be optimized for the specific platform, to achieve fast and efficient performance.
These challenges pose a large threat if not properly handled. On the one hand, the hardware limitations must be overcome in order to implement NNs on embedded platforms. On the other hand, the second part of challenges must be overcome so that the solution can be reached quickly, as time to market is key. Reverting to a hardware solution to accelerate time to market is also a very bad option, as it offers no flexibility, and will quickly become obsolete in the evolving neural networks field.
To find out how these obstacles can be hurdled quickly and effortlessly, tune in next time for part two. In it we’ll discuss and demonstrate our solutions, using GoogLeNet as an example.

Ceva