

7 min read
Simultaneous Localization and Mapping (SLAM) describes the process by which a device, such as a robot, uses sensor data to build a picture of its surrounding environment and simultaneously determine its position within that environment. There are many different ways of implementing SLAM, both in terms of the software algorithms deployed and also the sensors used, which may include cameras, Sonar, Radar, LiDAR and basic positional data, using an inertial measurement unit (IMU).
The availability of inexpensive and small cameras has driven the popularity of Monocular Visual SLAM systems, which use a single, standard camerato perform the location and mapping functions.Such visual SLAM systems can be found in a wide range of robots, including Mars rovers and landers, field robots in agriculture, drones and, potentially, autonomous vehicles. Visual SLAM systems also offer advantages where GPS is not available, for example in indoor areas or in big cities, where obstruction by buildings reduces GPS accuracy.
This article describes the basic visual SLAM process, covering the modules and the algorithms involved in object recognition and tracking and error correction. The advantages of offloading the SLAM computation and functionality to dedicated DSPs are discussed and the CEVA-SLAM SDK development kit is used as an illustration of the benefits that can be obtained by following this development route.
Direct and Feature-based SLAM
There are many different approaches to the implementation of visual SLAM, but all use the same overall method, tracking set points through consecutive camera frames to triangulate their 3D position whilst simultaneously using this information to approximate camera pose. In parallel, SLAM systems are continuously using complex algorithms to minimize the difference between projected and actual points – the reprojection error.
Visual SLAM systems can be classified as direct or feature-based, according to the way in which they use the information from a received image. Direct SLAM systems compare entire images to each other, providing rich information about the environment, enabling the creation of a more detailed map but at the expense of processing effort and speed. This article focuses on feature-based SLAM methods, which search the image for defined features, such as corners and “blobs” and base the estimation of location and surroundings only on these features. Although feature-based SLAM methods discard significant amounts of valuable information from the image, the trade-off is a simplified process that is computationally easier to implement.
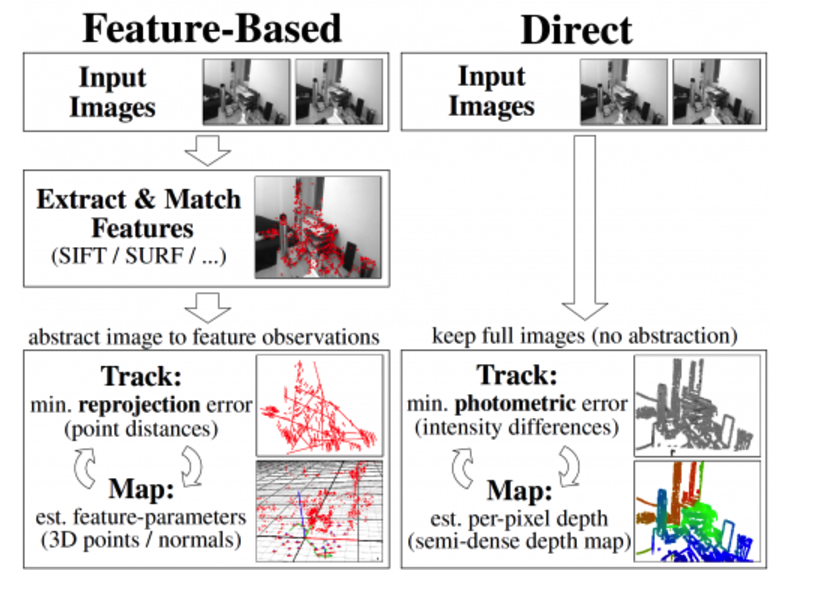
Figure 1: Direct vs Feature-based SLAM. (Source: https://vision.in.tum.de/research/vslam/lsdslam)
The visual SLAM Process
The main steps in feature-based SLAM are extraction of a set of sparse features from the input images, matching of the features obtained from different camera poses and solving of the SLAM problem by minimizing the feature reprojection error (the difference between a point’s tracked location and where it is expected to be given the camera pose estimate, over all points).
These steps are accomplished using a set of building blocks, described below, which are common to all feature-based SLAM implementations. Visual SLAM is an evolving area generating significant amounts of research and various algorithms have been developed and proposed for each module, each of which has pros and cons, depending on the exact nature of the SLAM implementation. The description below mentions a subset of the current, most popular algorithms.
Feature Extraction, figure 2, is a process which efficiently represents useful information in an image, such as corners, edges, blobs and more complex objects such as doorways and windows as a compact feature vector. Popular feature extraction algorithms include Difference of Gaussian (DoG) and Features from Accelerated Segment Test (FAST9), a corner detection method which is well suited to real-time video processing due to its computational efficiency.

Figure 2: SLAM Feature Extraction. (Source: https://medium.com/towards-artificial-intelligence/oriented-fast-and-rotated-brief-orb-1da5b2840768)
In Feature Description, the region around each extracted feature is converted into a compact descriptor that can be matched against other descriptors. Features may be described, for example, by their appearance, or by the intensity of the pixels in a patch around the feature point. ORB and FREAK are examples of popular feature descriptor algorithms.
In Feature Matching, extracted features (descriptors) are matched over multiple frames. Features are matched across two images by comparing all features in the first image to all features in the second image. The Hamming distance function is commonly used in Feature matching as it can be efficiently performed in hardware using the XoR and count-bits functions on bit sets of data such as vectors. The Hamming distance gives an indication of how many bits in two vectors are different, meaning that the lower the score, the closer the match.
Loop Closure is the final step in the SLAM process and ensures a consistent SLAM solution, particularly when localizing and mapping operations are conducted over a long period of time. Loop closure observes the same scene by non-adjacent frames and adds a constraint between them in order to reduce the accumulated drift in the pose estimate. As with the other visual SLAM modules, a variety of algorithms have been developed for loop closure, with the most popular ones being Bundle Adjustment, Kalman filtering and particle filtering.
VSLAM algorithms are an active research area and the above are examples of an increasing number of techniques which have emerged in recent years. Feature-based SLAM methods are preferable for embedded solutions since they enable faster processing speeds and make more efficient use of memory bandwidth. In addition, feature based solutions exhibit higher levels of robustness across a range of conditions, including rapid changes in brightness, low light levels, rapid camera movements and occlusions.
The choice of specific algorithm is driven by the characteristics of the particular application, including types of maps, sensor types, degree of accuracy required and many more. Many SLAM systems incorporate a combination of algorithms which best cater for the widest range of scenarios.
SLAM implementation challenges
Visual SLAM processing is extremely computationally intensive, placing high loads on traditional, CPU-based implementations, leading to excessive power consumption and low frame rates, with consequent impacts on accuracy and battery life. Developers of emerging SLAM applications require solutions that offer higher levels of integration and lower power consumption. They are increasingly using dedicated vision processing units (VPUs) in their designs. A VPU is a type of microprocessor with an architecture designed specifically for the acceleration of machine vision tasks, such as SLAM, and that can be used to offload the vision processing from the main application CPU. VPUs, such as CEVAs CEVA-XM6, figure 3, include features such as low power consumption, strong ALUs, powerful MAC capabilities, high throughput memory access, and dedicated vision instructions. The devices will also support the powerful floating-point capabilities required by image processing applications.
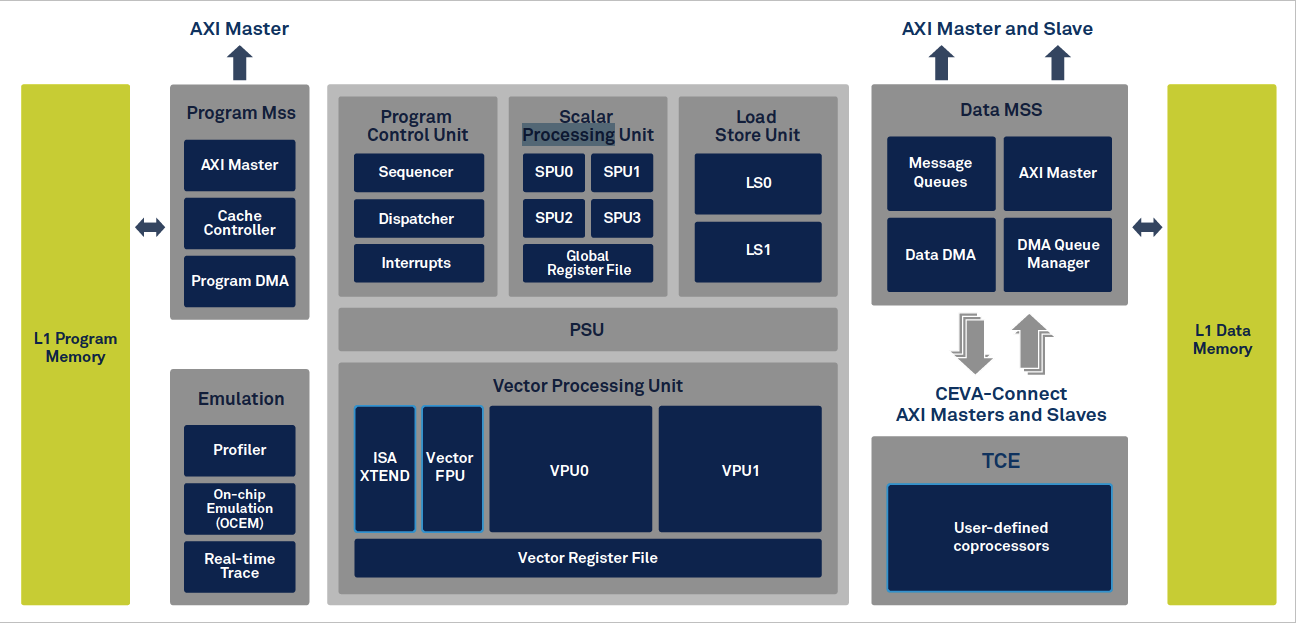
Figure 3: CEVA XM6 vision processing unit. (Source: CEVA)
Even with VPUs, however, the visual SLAM developer must still overcome several challenges since creating efficient code for the different SLAM modules is a non-trivial undertaking and it can also be difficult to interface the VPU to the main processor.
Creation of efficient code is crucial in embedded applications, where speed of execution and power consumption must be optimized. Coding of visual SLAM modules is a complex task, potentially requiring the fetching, storing and manipulation of large quantities of data. In feature matching, for example, descriptors are stored in memory as 128-bit vectors and, to match features across consecutive frames, 200 features must typically be compared with 2000 candidates, leading to 400,000 match operations. The matching operation obviously requires a large amount of memory but also, where the sampled data size is small, the high overhead of fetching and formatting the data can compromise the efficiency of the coded algorithm.
Bundle adjustment is another algorithm that involves complex linear algebra, involving the manipulation of large matrices. Various techniques exist to optimize coding for these and other VSLAM modules, but implementation of these techniques requires a high level of vision-specific coding expertise.
Memory management is another challenge in image processing. Data captured from an image is typically loaded into consecutive memory locations and working with random patches in an image means dealing with data that is not stored in consecutive memory locations. Software routines, which perform feature matching, must retrieve descriptors from non-consecutive memory locations, further increasing the set-up overhead.
VSLAM Development Tools
With speed-to-market critical in today’s environment it is not always practical for a developer to take the time to acquire the skills and knowledge required to implement efficient vision processing code. Fortunately a number of tools exist to facilitate the acceleration of cost-effective SLAM applications; application development kits are available which provide a combination of vision-specific software libraries, optimized hardware and integration tools to enable the developer to easily offload the vision specific tasks from the CPU to the VPU.
The CEVA SLAM SDK, figure 4, is a leading example of such an application development toolset.
Figure 4: The CEVA SLAM SDK. (Source: CEVA)
Based on the CEVA XM6 DSP and CEVA NeuPro AI processor hardware, the CEVA SLAM SDK enables the efficient integration of SLAM implementations into low-power embedded systems. The SDK features a number of building blocks including image processing libraries providing efficient code for feature detection and matching as well as bundle adjustment. It also provides support for linear algebra, linear equation solving, fast sparse equation solving and matrix manipulation.
The CEVA XM6 hardware is optimized for image processing with innovative features such as the parallel load instruction, which addresses the non-consecutive memory access problem, and also a unique, dedicated instruction for executing the Hamming Distance calculation. The SDK also includes a detailed CPU interface, enabling the developer to easily integrate the vision processing functionality with the main application CPU.
As an illustration of the performance of the SDK as a development tool, a reference implementation of a full SLAM tracking module running at 60 frames per second was measured to have a power consumption of only 86mW.
Conclusion
Visual SLAM systems are gaining popularity in a wide range of applications, such as agricultural field robots and drones. There are a number of alternative methods for the implementation of visual SLAM but, with the increasing deployment in embedded applications, efficiency of coding and low power consumption are critical factors.
Whilst it is common for developers to use VPUs to offload the compute-intensive vision processing tasks from the main CPU, significant challenges remain in order to produce efficient code and also to manage the interface between VPU and CPU.
With time to market a key driver, developers can accelerate product development by taking advantage of the capabilities built into SLAM-specific development toolkits such as the CEVA SLAM SDK.
Published on Embedded.com
Ceva